
В последние месяцы в AI-сообществе активно обсуждаются слухи о возможном появлении Fable 5 — сверхмощной языковой модели, которую ряд энтузиастов уже успел назвать следующим этапом развития генеративного искусственного интеллекта. Несмотря на отсутствие официального публичного релиза и многочисленные спекуляции вокруг проекта, сама дискуссия оказалась весьма показательной. Она вновь подняла вопрос, который сегодня волнует тысячи разработчиков: какими вычислительными ресурсами необходимо обладать для локального запуска моделей нового поколения?
Пока пользователи продолжают работать через облачные интерфейсы и API, многие компании все чаще рассматривают возможность развертывания AI-инфраструктуры на собственном VPS или выделенном сервере. Причина проста: контроль над данными, отсутствие ограничений по количеству запросов и возможность гибкой настройки системы под собственные задачи.
Еще несколько лет назад локальное развертывание крупных языковых моделей считалось привилегией исследовательских лабораторий. Однако развитие аппаратного обеспечения постепенно меняет ситуацию.
По оценкам различных аналитических агентств, объем мирового рынка искусственного интеллекта ежегодно растет более чем на 30%. Одновременно снижается стоимость вычислительных ресурсов, что делает локальное использование нейросетей доступным не только крупным корпорациям, но и среднему бизнесу.
Тем не менее между запуском небольшой модели и полноценной локализацией гипотетического AI-гиганта вроде Fable 5 лежит огромная технологическая пропасть. Если компактные модели способны работать даже на производительных рабочих станциях, то системы следующего поколения требуют инфраструктуры совершенно другого уровня.
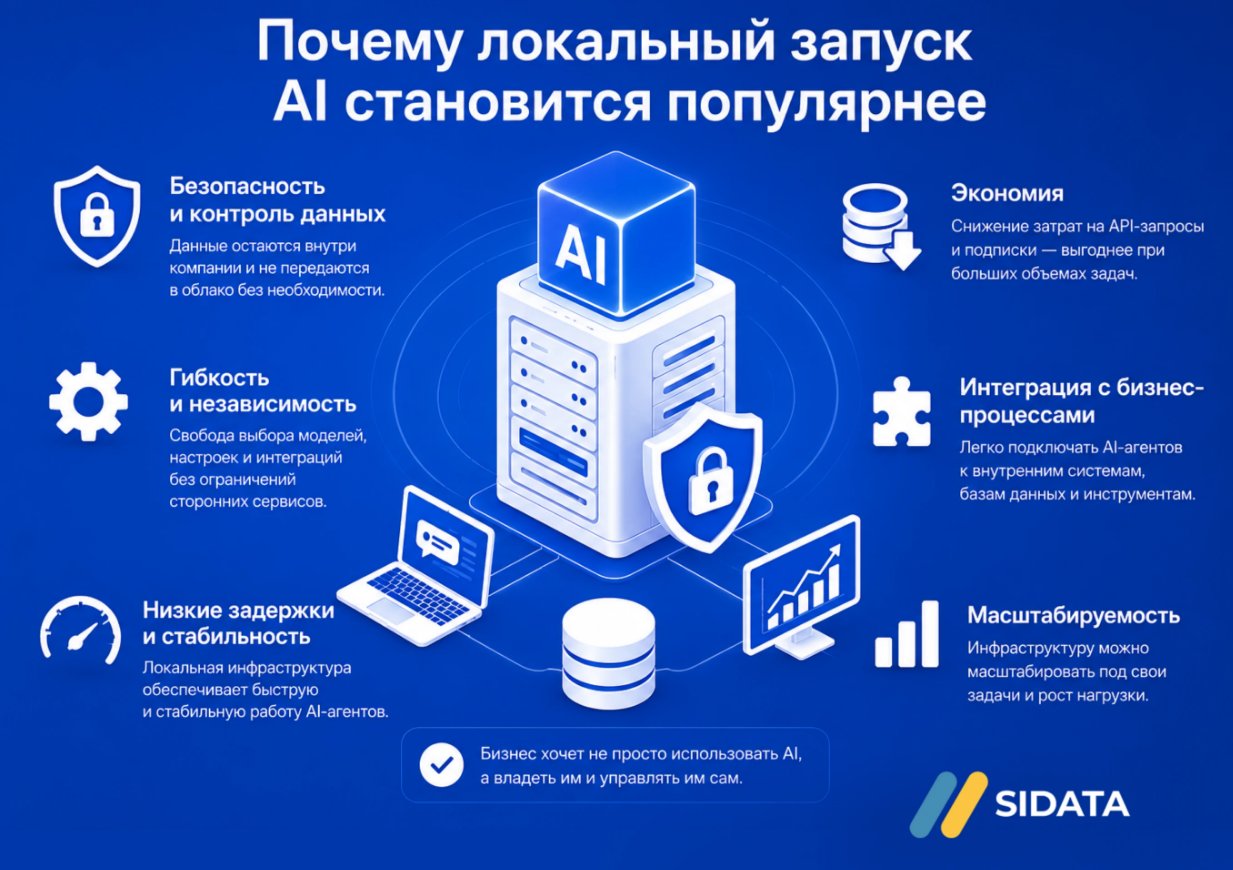
Когда речь заходит о локальном использовании современных LLM, многие ошибочно обращают внимание исключительно на объем оперативной памяти. На практике значение имеют сразу несколько факторов.
Наконец, ключевую роль играет наличие графических ускорителей. Сегодня большинство экспертов сходятся во мнении, что именно GPU стали главным двигателем революции генеративного искусственного интеллекта.
Не случайно генеральный директор компании NVIDIA Дженсен Хуанг неоднократно называл вычисления на GPU новой промышленной инфраструктурой цифровой экономики.
Если предположить, что Fable 5 действительно относится к классу наиболее продвинутых языковых моделей современности, ее локальный запуск потребует значительно больше ресурсов, чем большинство доступных сегодня решений.
Для экспериментальной работы с квантованной версией теоретически может хватить сервера уровня Dedicated с GPU, оснащенного несколькими современными ускорителями и большим объемом памяти.
Однако полноценная работа без агрессивного сжатия модели может потребовать уже целый кластер вычислительных узлов. Подобные решения сегодня используются крупнейшими технологическими компаниями мира для обслуживания собственных AI-сервисов.
В таком сценарии обычный Dedicated сервер выступает лишь частью инфраструктуры, а основная нагрузка распределяется между несколькими GPU-системами.
Чтобы лучше понимать масштаб необходимых ресурсов, полезно сравнить предполагаемые требования Fable 5 с уже существующими моделями.
| Модель | Минимальная конфигурация | Комфортная конфигурация | Рекомендации по масштабированию |
|---|---|---|---|
| Gemma 3 4B | 16 ГБ RAM | 32 ГБ RAM | При росте количества пользователей |
| Gemma 3 12B | 32 ГБ RAM | GPU 16–24 ГБ VRAM | Для работы с большими контекстами |
| Llama 3 8B | 32 ГБ RAM | GPU 24 ГБ VRAM | При активном использовании RAG |
| Llama 3 70B | 128 ГБ RAM | Несколько GPU по 48 ГБ VRAM | Для корпоративных внедрений |
| DeepSeek R1 | 128–256 ГБ RAM | Кластер GPU | Для интенсивной аналитики |
| Claude-уровень (гипотетически) | Несколько GPU | Серверный кластер | Для большого количества запросов |
| Fable 5 (предположительно) | Высокопроизводительный Dedicated с GPU | Кластер из нескольких GPU-серверов | Практически обязательное горизонтальное масштабирование |
Таблица наглядно показывает, насколько быстро растут требования по мере увеличения возможностей модели. Разница между компактной Gemma и системой условного уровня Fable 5 может измеряться уже не гигабайтами, а целыми стойками серверного оборудования.

Что выбрать сегодня для локализации?
На практике большинство компаний пока не нуждается в сверхмощных моделях. Для автоматизации поддержки клиентов, анализа документов, обработки заявок и создания внутренних AI-ассистентов вполне достаточно решений среднего уровня.
Чаще всего инфраструктура развивается поэтапно:
Такой подход позволяет контролировать затраты и постепенно увеличивать вычислительные мощности по мере роста нагрузки.
Даже если Fable 5 останется лишь предметом обсуждений, сама тенденция очевидна: каждое новое поколение искусственного интеллекта требует все более серьезной инфраструктуры. Для небольших моделей достаточно виртуального сервера, для продвинутых систем нужен Dedicated, а для AI следующего поколения все чаще рассматриваются Dedicated с GPU и полноценные вычислительные кластеры.
Поэтому главный вопрос уже не в том, смогут ли компании использовать сверхмощные модели локально, а в том, насколько быстро серверная инфраструктура будет успевать за развитием искусственного интеллекта.
iPhone 15 Pro – это сочетание передовых технологий и элегантного дизайна. В 2023 году Apple снова подняла планку,
Как правило, тотальное фотографирование и видеосъемка всего и вся, скачивание сотен музыкальных композиций из
В игровой консоли Microsoft Xbox One штатно уже установлен свой жесткий диск емкостью всего полтерабайта, что по







